

Are you curious about how edge computing differs from cloud computing or its relationship with the Internet of Things (IoT), this guide will break it all down in a simple and engaging way.
What is Edge Computing?
In 2025, the digital world will be inundated with data generated by billions of devices. Ericsson estimates that the global number of smartphones will surpass 7 billion, while the International Data Corporation (IDC) predicts there will be 41.6 billion Internet of Things (IoT) devices in use by the same year. These IoT devices alone are expected to produce nearly 80 zettabytes of data annually, equivalent to about 200 million terabytes daily.
This surge in data presents significant challenges for existing infrastructure. Traditional centralized systems, such as cloud computing, may struggle to manage the massive data volume due to bandwidth constraints, latency issues, and network congestion. Transmitting all this data to distant cloud servers for processing not only increases costs but also delays real-time decision-making—critical for applications like autonomous vehicles and industrial automation.
One solution to this challenge is edge computing, a distributed model that processes data closer to its source. By enabling local processing on edge devices—such as IoT sensors, gateways, and local servers—edge computing reduces the need for constant data transmission to centralized servers. This approach optimizes bandwidth, minimizes latency, and ensures real-time responsiveness for critical applications. For instance, self-driving cars use edge computing to process sensor data locally and make split-second decisions without relying on remote servers.
As billions of devices generate unprecedented amounts of data, edge computing will play a crucial role in maintaining efficient and responsive networks while addressing the challenges posed by this digital explosion.
At its core, edge computing refers to a distributed computing model that processes data near the source of its generation—at the “edge” of the network. Instead of sending all data to centralized cloud servers for processing, edge devices such as sensors, gateways, or local servers handle it locally. This approach reduces latency, saves bandwidth, and enables real-time decision-making.
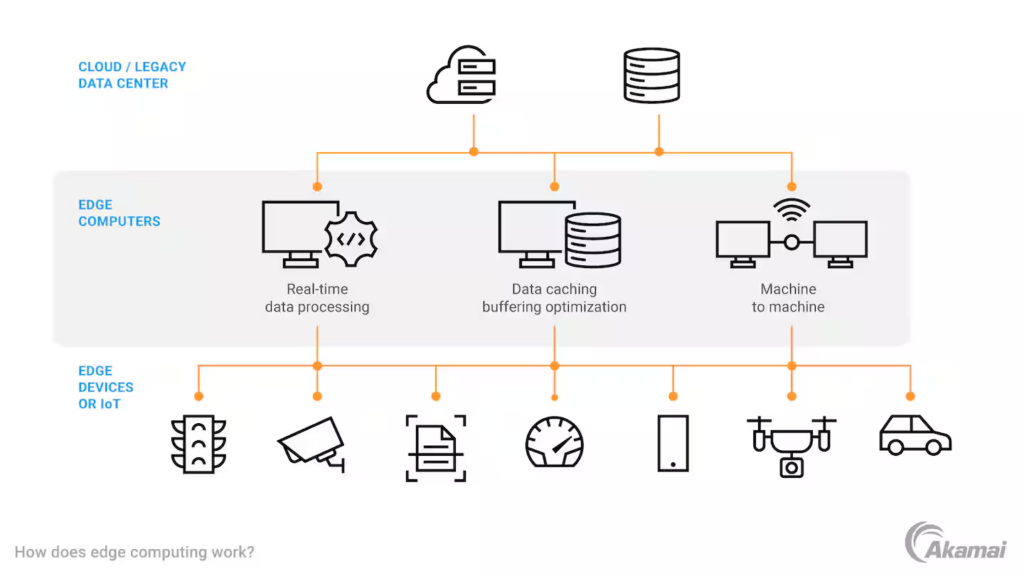
How Does Edge Computing Work?
Data Generation at the Edge
Edge computing begins with edge devices—these are the endpoints where data is generated. Examples include IoT sensors, cameras, smart appliances, and industrial machines. These devices collect raw data from their environment, such as temperature readings, video footage, or equipment performance metrics. A smart thermostat in a home collects temperature data to adjust heating or cooling settings.
Local Data Processing
Instead of sending all collected data to a centralized cloud server for analysis, edge computing processes it locally on the device itself or through nearby computing resources like edge gateways or edge servers.
- Edge Devices: Many edge devices have built-in processors capable of performing basic computations. For example, a smartwatch can analyze heart rate data locally to alert users about irregularities.
- Edge Gateways: These act as intermediaries between edge devices and larger systems. They aggregate and filter data from multiple devices before sending only relevant or summarized information further up the chain.
- Edge Servers: These are more powerful than individual devices and can handle complex computations locally. For instance, an edge server in a factory might analyze sensor data from multiple machines to predict maintenance needs
Connectivity
Reliable connectivity is essential for edge computing systems to function effectively. Networks like Wi-Fi, 5G, or low-power wide-area networks (LPWAN) enable communication between edge devices, gateways, and servers.
Technologies like 5G are particularly significant for edge computing as they provide high-speed, low-latency connections that support real-time applications such as autonomous vehicles or remote surgeries.
Selective Data Transmission
Once the local processing is complete, only critical or summarized data is sent to the cloud or central data centers for further analysis or long-term storage. This reduces bandwidth usage and network congestion while ensuring that essential insights are acted upon immediately.
In a smart city scenario, traffic cameras might process video feeds locally to manage traffic lights in real time while sending broader traffic patterns to the cloud for city-wide planning.
Real-Time Decision-Making
One of the most significant benefits of edge computing is its ability to enable real-time decision-making. By processing data locally and minimizing latency caused by long-distance communication with cloud servers, edge systems can respond almost instantaneously.
In autonomous vehicles, edge computing allows sensors and cameras to process environmental data locally and make split-second decisions like braking or steering adjustments without waiting for instructions from a remote server
Edge Computing and Fog Computing
Edge computing and fog computing are often discussed together as they both aim to bring data processing closer to the source of data generation, reducing reliance on centralized cloud systems. However, they are not the same and have distinct differences in terms of architecture, purpose, and implementation.
| Aspect | Edge Computing | Fog Computing |
|---|---|---|
| Definition | Processes data directly on devices (e.g., sensors, IoT devices) or at a gateway close to the data source. | Acts as an intermediary layer between edge devices and the cloud, processing data within fog nodes or IoT gateways. |
| Location of Processing | Data is processed on the device itself or at a nearby gateway. | Data is processed within a local area network (LAN) or fog nodes, which are closer to the cloud than edge devices. |
| Scalability | Less scalable due to limited device capabilities. | More scalable as it integrates multiple edge nodes and connects them to the cloud. |
| Latency | Extremely low latency, ideal for real-time applications like autonomous vehicles or industrial automation. | Slightly higher latency compared to edge computing but still lower than cloud computing. |
| Bandwidth Usage | Reduces bandwidth usage significantly by processing data locally and transmitting only necessary data. | Filters and preprocesses data before sending it to the cloud, optimizing bandwidth usage further. |
| Power and Resources | Limited power and storage capabilities since processing happens on smaller devices. | Offers more computational power as fog nodes are larger and can handle more extensive processing tasks. |
| Dependency on Cloud | Can operate independently of the cloud for real-time decision-making. | Acts as an extension of the cloud, balancing workloads between edge devices and centralized servers. |
While edge computing focuses on processing data at or near the source (e.g., IoT sensors or devices), fog computing extends this functionality by adding an intermediate layer between edge devices and the cloud. This layer—fog nodes—aggregates, filters, and processes data from multiple edge devices before sending only critical information to the cloud.
In a smart city, edge computing might process real-time traffic data from cameras at intersections to control traffic lights immediately. Fog computing would then aggregate this data from multiple intersections to provide insights into city-wide traffic patterns, which can be stored in the cloud for future analysis.
Edge Computing vs. Cloud Computing
While both edge and cloud computing aim to process and analyze data efficiently, they differ significantly in their architecture and use cases.
| Feature | Edge Computing | Cloud Computing |
|---|---|---|
| Location of Processing | Close to the data source (e.g., IoT devices) | Centralized in remote data centers |
| Latency | Low latency; ideal for real-time tasks | Higher latency due to distance |
| Bandwidth Usage | Reduces bandwidth by processing locally | Requires more bandwidth for large datasets |
| Scalability | Limited scalability | Highly scalable |
| Use Cases | Autonomous vehicles, smart cities | Big data analytics, collaborative tools |
Complementary Use:
Many organizations combine both models for optimal performance. For example, edge computing handles time-sensitive tasks locally while cloud computing manages long-term storage and complex analytics.
Advantages and Disadvantages of Edge Computing
Advantages:
- Reduced Latency: By processing data locally, edge computing eliminates delays caused by transmitting data to distant servers.
- Improved Reliability: Localized processing ensures that critical operations continue even during network disruptions.
- Enhanced Security: Sensitive data can be processed on-site without being transmitted over potentially insecure networks.
- Cost Efficiency: Reduces bandwidth costs by minimizing the amount of data sent to the cloud.
- Real-Time Insights: Ideal for applications requiring immediate responses, such as industrial automation or healthcare monitoring.
Disadvantages:
- Higher Costs: Specialized hardware and infrastructure at the edge can be expensive.
- Complex Management: Managing numerous distributed devices requires advanced expertise.
- Limited Storage and Power: Edge devices often have less capacity compared to centralized cloud servers.
- Security Challenges: While localized processing reduces some risks, edge devices themselves can be vulnerable to cyberattacks.
What is the Internet of Things (IoT)?
The Internet of Things (IoT) refers to a network of interconnected physical devices embedded with sensors, software, and connectivity features that enable them to collect and exchange data autonomously.
Examples of IoT Devices:
- Smart home gadgets like thermostats or security cameras
- Wearable health monitors such as fitness trackers
- Industrial machinery equipped with performance sensors
- Connected vehicles with real-time navigation systems
IoT and Edge Computing: A Synergistic Relationship
While IoT generates massive amounts of data from connected devices, edge computing ensures this data is processed efficiently without overwhelming centralized systems. For instance:
- In smart cities, IoT sensors monitor traffic flow while edge nodes process this information locally to adjust traffic lights in real time.
- In agriculture, IoT devices track soil conditions while edge systems analyze the data on-site to optimize irrigation schedules.
Key Use Cases of Edge Computing
- Autonomous Vehicles:
- Real-time decision-making for navigation and safety
- Ultra-low latency communication between vehicles
- Healthcare:
- Remote patient monitoring with instant alerts for abnormalities
- On-site analysis of medical imaging
- Industrial Automation:
- Predictive maintenance by analyzing equipment performance locally
- Real-time optimization of manufacturing processes
- Smart Cities:
- Traffic management through real-time sensor inputs
- Energy optimization in smart grids
- Retail:
- Personalized shopping experiences using in-store analytics
- Inventory management through IoT-enabled shelves
Edge computing represents a paradigm shift in how we process and analyze data in a world increasingly dominated by IoT devices and real-time applications. By bringing computation closer to where it’s needed most—at the edge—it addresses challenges like latency, bandwidth limitations, and reliability that traditional cloud models struggle with.
However, it’s not without its challenges higher costs and complexity require careful planning before implementation. As industries continue to adopt technologies like autonomous vehicles and smart cities, the synergy between edge computing and IoT will only grow stronger.
Whether you’re an enterprise looking to optimize operations or an individual curious about emerging tech trends, understanding edge computing is key to staying ahead in today’s digital age!